
はじめまして、データサイエンティストのますみです!

この記事は”Zenn”という技術記事や本を書いて出版することのできるサービスをPythonでスクレイピング / データ分析していく記事になります。
「本の表紙(装丁)をデザインする人」や「記事や本のタイトルを決める人」に向けて、人気の本の共通点を分析していきたいと思います👍
スクレイピングは、同じサーバーにアクセスしすぎると、サーバーに負荷を与えてしまう可能性があります。そのため、しっかりと数秒間隔を空けてアクセスするようにしましょう。
また、データ分析の目的ではなく、不特定多数の人が使うサービスを目的としたスクレイピングはあまり好ましくないため、ご注意ください。
実行環境
| Type | Version |
|---|---|
| OS | macOS Catalina v10.15.7 |
| Python | v3.6.5 |
| Selenium | v3.141.0 |
| Chrome Driver | v87.0.4280.88 |
全体の流れ
- スクレイピングの準備
- 全書籍を読み込み
- タイトル / 表紙画像リンク / お気に入り数 / 値段を取得
- 有料 / 無料本それぞれの人気トップ10を表示
- 人気本の特徴を分析
スクレイピング方法解説
1. スクレイピングの準備
1-A. Pythonのインストール
まだPythonの環境構築ができていない方は、こちらの記事を参考にして準備しましょう。
【macOSの方々】

【Windowsの方々】
参考 Pythonの開発環境を用意しよう!(Windows)Progate – プログラミングで人生の可能性を広げよう
1-B. Seleniumのインストール
Terminalで以下のコマンドを実行しましょう。また、pandasもこの後使っていくため、pandasもインストールしましょう。
$ pip install selenium pandas
1-C. Chrome Driverのインストール
まず現在使用しているGoogle Chromeのバージョンを以下のリンクから確認します。
次に、現在のバージョンに相当するChrome Driverを以下のリンクからダウンロードしましょう。
https://sites.google.com/a/chromium.org/chromedriver/downloads

1-D. スクリーンショットを取得してみよう
それでは、実際にコーディングをしていきましょう。
以下のようなmain.pyというファイルを作成しましょう。
from selenium import webdriver
# Create and Get Driver
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://zenn.dev/books')
# Take Screenshots
driver.save_screenshot("screenshot.png")
# Close and Quit Driver
driver.close()
driver.quit()main.pyが完成したら、先ほどダウンロードしたzipファイルを解凍して、main.pyと同じディレクトリに移動しましょう。そのディレクトリで以下のようなコマンドを実行すると、スクリーショットがscreenshot.pngという名前で保存されると思います。もしも保存されたら実行成功です!
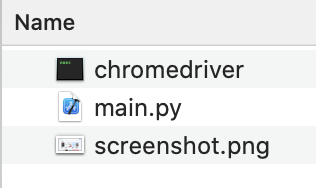
以下のようなエラーが出た時は、chromedriverに対してシステム環境設定 > セキュリティとプライバシーで許可する手法で解消されると思います。
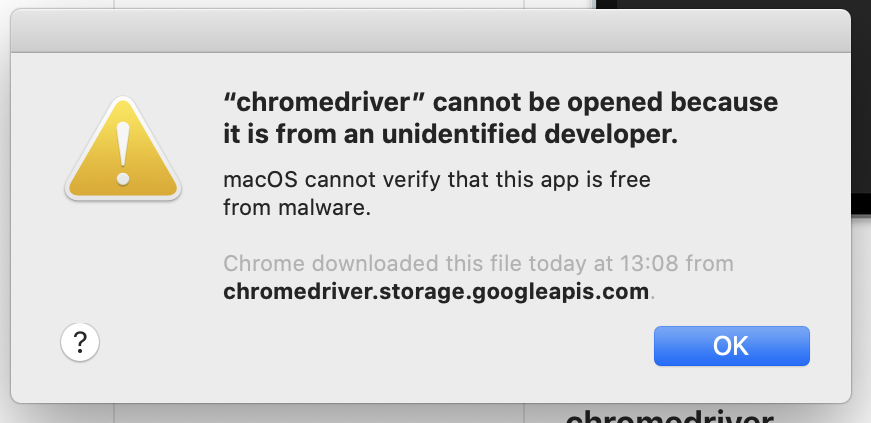
以下のような手順で許可します。
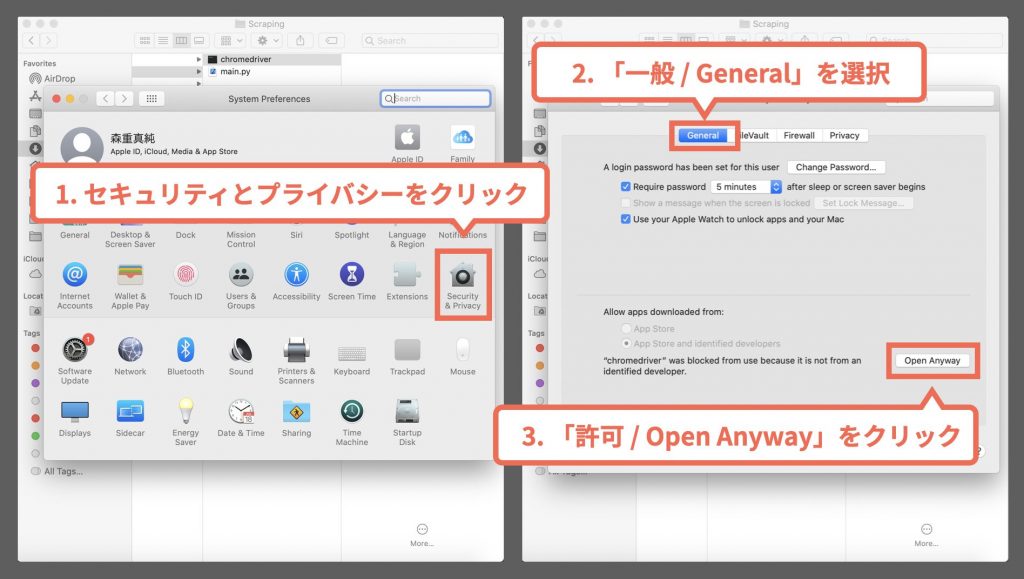
また、今回はhomebrewを使っていないため、以下のようなエラーが出る人は少ないと思いますが、Homebrew Cask downloaded this file today at xx:xx from sites.google.comというメッセージが表示されている場合も、システム環境設定 > セキュリティとプライバシーでchromedriverを許可する手法で解消されます。
2. 全書籍を読み込み
次に、全書籍が読み込まれた状態にするために、以下のように最下部の「もっとみる」のボタンをクリックし続けるプログラムを書きます。
from selenium import webdriver
import time
# Create and Get Driver
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://zenn.dev/books')
# Get Load Button
while driver.find_elements_by_xpath("/html/body/div/section/div[2]/button"):
load_buttons = driver.find_elements_by_xpath("/html/body/div/section/div[2]/button")
load_buttons[0].click()
time.sleep(3)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
print("Load Completed.")
# Close and Quit Driver
# driver.close()
# driver.quit()以下のように「もっとみる」が消えるまでスクロールされれば成功です!

3. タイトル / 表紙画像リンク / お気に入り数 / 値段を取得
次に「タイトル / 表紙画像リンク / お気に入り数 / 値段」を取得して、CSVに保存したいと思います。以下のようなコードに編集しましょう。
from selenium import webdriver
import time
import pandas as pd
# Create and Get Driver
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://zenn.dev/books')
try:
# Get Load Button
while driver.find_elements_by_xpath("/html/body/div/section/div[2]/button"):
load_buttons = driver.find_elements_by_xpath("/html/body/div/section/div[2]/button")
load_buttons[0].click()
time.sleep(3)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
print("Load Completed.")
# Get Article Information
articles = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article")
print("=====")
df = pd.DataFrame(index=[], columns=['title', 'img', 'favorite', 'price'])
for article_index in range(len(articles)):
title_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/h3")
title = title_element[0].text
img_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/div/img")
img = img_element[0].get_attribute("src")
fav_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[2]/div[2]/span")
fav = fav_element[0].text if fav_element else 0
price_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/div/div/span")
price = price_element[0].text
price = price[1:]
df = df.append({'title':title, 'img': img, 'favorite': int(fav), 'price': int(price)}, ignore_index=True)
df.to_csv('./master.csv')
# Close and Quit Driver
driver.close()
driver.quit()
except Exception as e:
print(e)
driver.close()
driver.quit()以下のようなtitle、img、favorite、priceの4つの値が入ったマスターシートが出てきたら、成功です!
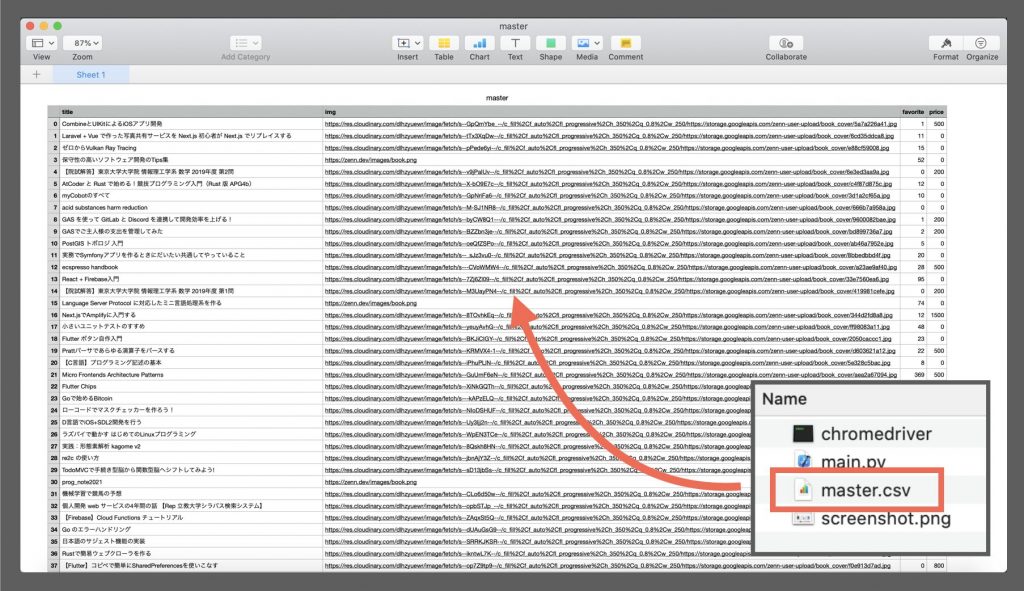
4. 有料 / 無料本それぞれの人気トップ10を表示
最後に、有料 / 無料本それぞれの人気トップ10を抽出して、CSVに保存しましょう。以下のようなコードに編集します。
from selenium import webdriver
import time
import pandas as pd
# Create and Get Driver
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://zenn.dev/books')
try:
# Get Load Button
while driver.find_elements_by_xpath("/html/body/div/section/div[2]/button"):
load_buttons = driver.find_elements_by_xpath("/html/body/div/section/div[2]/button")
load_buttons[0].click()
time.sleep(3)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
print("Load Completed.")
# Get Article Information
articles = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article")
print("=====")
df = pd.DataFrame(index=[], columns=['title', 'img', 'favorite', 'price'])
for article_index in range(len(articles)):
title_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/h3")
title = title_element[0].text
img_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/div/img")
img = img_element[0].get_attribute("src")
fav_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[2]/div[2]/span")
fav = fav_element[0].text if fav_element else 0
price_element = driver.find_elements_by_xpath("/html/body/div/section/div[1]/div/div/article[" + str(article_index+1) + "]/a[1]/div/div/span")
price = price_element[0].text
price = price[1:]
df = df.append({'title':title, 'img': img, 'favorite': int(fav), 'price': int(price)}, ignore_index=True)
# Sort Non-Free Articles
df_non_free = df[df['price'] != 0]
df_non_free = df_non_free.sort_values(['favorite', 'price'], ascending=[False, False])
# Sort Free Articles
df_free = df[df['price'] == 0]
df_free = df_free.sort_values(['favorite', 'price'], ascending=[False, False])
# Export to CSV
df.to_csv('./master.csv')
df_non_free[0:10].to_csv('./non_free.csv')
df_free[0:10].to_csv('./free.csv')
# Close and Quit Driver
driver.close()
driver.quit()
except Exception as e:
print(e)
driver.close()
driver.quit()以下のようにfree.csvとnon_free.csvというCSVファイルが出力されたら、成功です!
5. 人気本の特徴を分析
5-A. タイトルから分析
現時点(2020年1月3日 時点)の人気トップ10の有料記事 / 無料記事のタイトルは以下の通りでした。
| 有料 | 無料 |
|---|---|
| 1. Micro Frontends Architecture Patterns | 1. Gatsby入門 |
| 2. 2020年版: なぜ仮想 DOM / 宣言的 UI という概念が、あのときの俺達の魂を震えさせたのか | 2. プログラマのための英語表現 |
| 3. Origin 解体新書 v1.5.2 | 3. Nuxt.js + Ruby on Rails + AWS Fargate の開発・デプロイチュートリアル |
| 4. 競馬予想で始める機械学習〜完全版〜 | 4. Webpackの入門書 |
| 5. RustでつくるGit入門 | 5. Kubernetesネットワーク 徹底解説 |
| 6. Next.jsとFirebaseで質問箱のようなサービスを作る | 6. ヒヨコでもわかる TCP/IP 超入門 |
| 7. 普段使いから始めるNext.js | 7. チームにdockerを布教することになったので、布教の教材を作ってみた。 |
| 8. Go 言語にやってくる Generics は我々に何をもたらすのか | 8. Zennで本を執筆する!本の作成マニュアル |
| 9. Firebase Cloud Firestore Security Rules Essentials | 9. 伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門 |
| 10. React と Vue に関する XSS アンチパターン | 10. プログラマの心の健康(抜粋) |
5-B. 表紙から分析
現時点(2020年1月3日 時点)の人気トップ5の有料記事 / 無料記事の表紙は以下の通りでした。

5-C. 発見 / 考察 / 感想
表紙や値段などの交絡因子が多いため、一概にタイトルだけからは判断できませんが、今回のスクレイピングを通した気付きとしては、以下のようなものがあげられる。
- 無料本では、入門記事が上位にランクイン
- 有料本では、アーキテクチャやCORSなどの専門的なことに関連した本がランクイン
- 文字と背景のコントラストがついている本がランクイン
- 作者などの情報を省き、タイトルだけを表紙に入れている本が多い
今後の展望
今回は簡易的な分析を行ったがより本格的な分析をするとしたら、以下のようなアプローチが考えられます。
- 出版日 / 技術カテゴリ / 作者の影響力 / 本の文字数を考慮
- 売れる本の表紙を敵対的生成ネットワーク(GAN)などを用いて生成
- 人気のある本のカテゴリを分析
- 人気のある本の「はじめに」などの第1章を分析
最後に
いかがだったでしょうか?
この記事を通して、少しでもあなたの困りごとが解決したら嬉しいです^^
📩 仕事の相談はこちら 📩
お仕事の相談のある方は、下記のフォームよりお気軽にご相談ください。
問い合わせフォームはこちら
もしもメールでの問い合わせの方がよろしければ、下記のメールアドレスへご連絡ください。
info*galirage.com(*を@に変えてご送付ください)
🎁 「生成AIの社内ガイドライン」PDFを『公式LINE』で配布中 🎁
「LINEで相談したい方」や「お問い合わせを検討中の方」は、公式LINEでご連絡いただけますと幸いです。
(期間限定で配信中なため、ご興味ある方は、今のうちに受け取りいただけたらと思います^^)
公式LINEはこちら
🚀 新サービス開始のお知らせ 🚀
新サービス 「AI Newsletter for Biz」 がスタートしました!
ビジネスパーソン向けに「AIニュース」を定期配信する完全無料のニュースレターです📩
ますみが代表を務める「株式会社Galirage」では、「生成AIを用いたシステムの受託開発(アドバイス活動含む)」をしています。
そこでお世話になっているお客様に対して、「最新トレンドを加味したベストな提案」をするために、日々最新ニュースを収集する仕組みを構築していました。
今回は、そこで構築した仕組みを活用して、より多くの人に有益な情報を届けたいと思い、本サービスを開始しました!
一人でも多くの方にとって、「AI人材としてのスキルアップ」につながれば幸いです^^
▼ 登録はこちらから ▼
https://bit.ly/ai_newsletter_for_biz_ai_lab


